Posts
Wiki Contributions
Comments
Superalignment likely happened because (a) the safety faction (Ilya/Jan/etc.) wanted it, and (b) the Sam faction also wanted it, or tolerated it, or agreed to it due to perceived PR benefits (safety-washing), or let it happen as a result of internal negotiation/compromise, or something else, or some combination of these things.
Sure, that's basically my model as well. But if the faction (b) only cares about alignment due to perceived PR benefits or in order to appease faction (a), and faction (b) turns out to have overriding power such that it can destroy or drive out faction (a) and then curtail all the alignment efforts, I think it's fair to compress all that into "OpenAI's alignment efforts are safety-washing". If (b) has the real power within OpenAI, then OpenAI's behavior and values can be approximately rounded off to (b)'s behavior and values, and (a) is a rounding error.
If OAI as a whole was really only doing anything safety-adjacent for pure PR or virtue signaling reasons, I think its activities would have looked pretty different
Not if (b) is concerned about fortifying OpenAI against future challenges, such as hypothetical futures in which the AGI Doomsayers get their way and the government/the general public wakes up and tries to nationalize or ban AGI research. In that case, having a prepared, well-documented narrative of going above and beyond to ensure that their products are safe, well before any other parties woke up to the threat, will ensure that OpenAI is much more well-positioned to retain control over its research.
(I interpret Sam Altman's behavior at Congress as evidence for this kind of longer-term thinking. He didn't try to downplay the dangers of AI, which would be easy and what someone myopically optimizing for short-term PR would. He proactively brought up the concerns that future AI progress might awaken, getting ahead of it, and thereby established OpenAI as taking them seriously and put himself into the position to control/manage these concerns.)
And it's approximately what I would do, at least, if I were in charge of OpenAI and had a different model of AGI Ruin.
And this is the potential plot whose partial failure I'm currently celebrating.
That's good news.
There was a brief moment, back in 2023, when OpenAI's actions made me tentatively optimistic that the company was actually taking alignment seriously, even if its model of the problem was broken.
Everything that happened since then has made it clear that this is not the case; that all these big flashy commitments like Superalignment were just safety-washing and virtue signaling. They were only going to do alignment work inasmuch as that didn't interfere with racing full-speed towards greater capabilities.
So these resignations don't negatively impact my p(doom) in the obvious way. The alignment people at OpenAI were already powerless to do anything useful regarding changing the company direction.
On the other hand, what these resignations do is showcasing that fact. Inasmuch as Superalignment was a virtue-signaling move meant to paint OpenAI as caring deeply about AI Safety, so many people working on it resigning or getting fired starkly signals the opposite.
And it's good to have that more in the open; it's good that OpenAI loses its pretense.
Oh, and it's also good that OpenAI is losing talented engineers, of course.
I think you're imagining that we modify the shrink-and-reposition functions each iteration, lowering their scope? I. e., that if we picked the topmost triangle for the first iteration, then in iteration two we pick one of the three sub-triangles making up the topmost triangle, rather than choosing one of the "highest-level" sub-triangles?
Something like this:

If we did it this way, then yes, we'd eventually end up jumping around an infinitesimally small area. But that's not how it works, we always pick one of the highest-level sub-triangles:
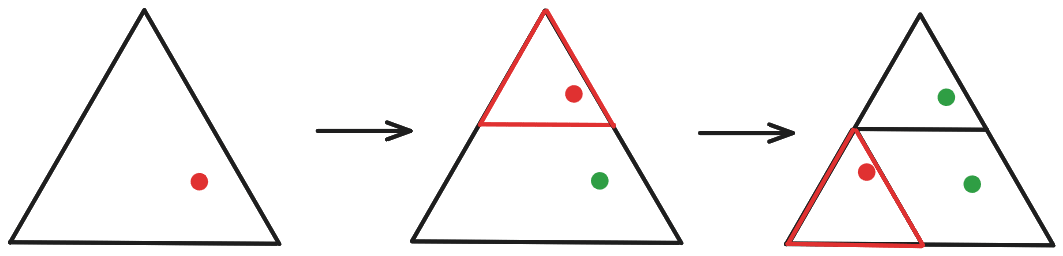
Note also that we take in the "global" coordinates of the point we shrink-and-reposition (i. e., its position within the whole triangle), rather than its "local" coordinates (i. e., position within the sub-triangle to which it was copied).
Here's a (slightly botched?) video explanation.
I'd say one of the main reasons is because military-AI technology isn't being optimized towards things we're afraid of. We're concerned about generally intelligent entities capable of e. g. automated R&D and social manipulation and long-term scheming. Military-AI technology, last I checked, was mostly about teaching drones and missiles to fly straight and recognize camouflaged tanks and shoot designated targets while not shooting not designated targets.
And while this still may result in a generally capable superintelligence in the limit (since "which targets would my commanders want me to shoot?" can be phrased as a very open-ended problem), it's not a particularly efficient way to approach this limit at all. Militaries, so far, just aren't really pushing in the directions where doom lies, while the AGI labs are doing their best to beeline there.
The proliferation of drone armies that could be easily co-opted by a hostile superintelligence... It doesn't have no impact on p(doom), but it's approximately a rounding error. A hostile superintelligence doesn't need extant drone armies; it could build its own, and co-opt humans in the meantime.
I think that the key thing we want to do is predict the generalization of future neural networks.
It's not what I want to do, at least. For me, the key thing is to predict the behavior of AGI-level systems. The behavior of NNs-as-trained-today is relevant to this only inasmuch as NNs-as-trained-today will be relevant to future AGI-level systems.
My impression is that you think that pretraining+RLHF (+ maybe some light agency scaffold) is going to get us all the way there, meaning the predictive power of various abstract arguments from other domains is screened off by the inductive biases and other technical mechanistic details of pretraining+RLHF. That would mean we don't need to bring in game theory, economics, computer security, distributed systems, cognitive psychology, business, history into it – we can just look at how ML systems work and are shaped, and predict everything we want about AGI-level systems from there.
I disagree. I do not think pretraining+RLHF is getting us there. I think we currently don't know what training/design process would get us to AGI. Which means we can't make closed-form mechanistic arguments about how AGI-level systems will be shaped by this process, which means the abstract often-intuitive arguments from other fields do have relevant things to say.
And I'm not seeing a lot of ironclad arguments that favour "pretraining + RLHF is going to get us to AGI" over "pretraining + RLHF is not going to get us to AGI". The claim that e. g. shard theory generalizes to AGI is at least as tenuous as the claim that it doesn't.
Flagging that this is one of the main claims which we seem to dispute; I do not concede this point FWIW.
I'd be interested if you elaborated on that.
I wouldn't call Shard Theory mainstream
Fair. What would you call a "mainstream ML theory of cognition", though? Last I checked, they were doing purely empirical tinkering with no overarching theory to speak of (beyond the scaling hypothesis[1]).
judging by how bad humans are at [consistent decision-making], and how much they struggle to do it, they probably weren't optimized too strongly biologically to do it. But memetically, developing ideas for consistent decision-making was probably useful, so we have software that makes use of our processing power to be better at this
Roughly agree, yeah.
But all of this is still just one piece on the Jenga tower
I kinda want to push back against this repeat characterization – I think quite a lot of my model's features are "one storey tall", actually – but it probably won't be a very productive use of the time of either of us. I'll get around to the "find papers empirically demonstrating various features of my model in humans" project at some point; that should be a more decent starting point for discussion.
What I want is to build non-Jenga-ish towers
Agreed. Working on it.
- ^
Which, yeah, I think is false: scaling LLMs won't get you to AGI. But it's also kinda unfalsifiable using empirical methods, since you can always claim that another 10x scale-up will get you there.
the model chose slightly wrong numbers
The engraving on humanity's tombstone be like.
The sort of thing that would change my mind: there's some widespread phenomenon in machine learning that perplexes most, but is expected according to your model
My position is that there are many widespread phenomena in human cognition that are expected according to my model, and which can only be explained by the more mainstream ML models either if said models are contorted into weird shapes, or if they engage in denialism of said phenomena.
Again, the drive for consistent decision-making is a good example. Common-sensically, I don't think we'd disagree that humans want their decisions to be consistent. They don't want to engage in wild mood swings, they don't want to oscillate wildly between which career they want to pursue or whom they want to marry: they want to figure out what they want and who they want to be with, and then act consistently with these goals in the long term. Even when they make allowances for changing their mind, they try to consistently optimize for making said allowances: for giving their future selves freedom/optionality/resources.
Yet it's not something e. g. the Shard Theory would naturally predict out-of-the-box, last I checked. You'd need to add structures on top of it until it basically replicates my model (which is essentially how I arrived at my model, in fact – see this historical artefact).
I find the idea of morality being downstream from the free energy principle very interesting
I agree that there are some theoretical curiosities in the neighbourhood of the idea. Like:
- Morality is downstream of generally intelligent minds reflecting on the heuristics/shards.
- Which are downstream of said minds' cognitive architecture and reinforcement circuitry.
- Which are downstream of the evolutionary dynamics.
- Which are downstream of abiogenesis and various local environmental conditions.
- Which are downstream of the fundamental physical laws of reality.
- Which are downstream of abiogenesis and various local environmental conditions.
- Which are downstream of the evolutionary dynamics.
- Which are downstream of said minds' cognitive architecture and reinforcement circuitry.
Thus, in theory, if we plug all of these dynamics one into another, and then simplify the resultant expression, we should actually get a (probability distribution over) the utility function that is "most natural" for this universe to generate! And the expression may indeed be relatively simple and have something to do with thermodynamics, especially if some additional simplifying assumptions are made.
That actually does seem pretty exciting to me! In an insight-porn sort of way.
Not in any sort of practical way, though[1]. All of this is screened off by the actual values actual humans actually have, and if the noise introduced at every stage of this process caused us to be aimed at goals wildly diverging from the "most natural" utility function of this universe... Well, sucks to be that utility function, I guess, but the universe screwed up installing corrigibility into us and the orthogonality thesis is unforgiving.
- ^
At least, not with regards to AI Alignment or human morality. It may be useful for e. g. acausal trade/acausal normalcy: figuring out the prior for what kinds of values aliens are most likely to have, etc.[2]
- ^
Or maybe for roughly figuring out what values the AGI that kills us all is likely going to have, if you've completely despaired of preventing that, and founding an apocalypse cult worshiping it. Wait a minute...
OpenAI enthusiastically commercializing AI + the "Superalignment" approach being exactly the approach I'd expect someone doing safety-washing to pick + the November 2023 drama + the stated trillion-dollar plans to increase worldwide chip production (which are directly at odds with the way OpenAI previously framed its safety concerns).
Some of the preceding resignations (chiefly, Daniel Kokotajlo's) also played a role here, though I didn't update off of them much either.